
즐겁게, 코드
파이썬과 함께 국장 정글에서 살아남기 본문
특별한 내용은 없는 일상글인데, 꽤나 신기한 경험이었어서 간단히 적어본다.

어렸을 때는 주식이 패가망신의 상징(?) 과도 비슷한 이미지였던 것 같은데 요즘은 어떤 모임이든 최소 두어명은 주식을 하는 것 같다.
나도 국내상장 해외 ETF들에 투자하고 있는데, 갑자기 "소프트웨어를 활용하면 지수 이상의 수익률을 낼 수 있지 않을까?" 라는 호기심이 생겼다.
파이썬으로 구현하는 로보어드바이저 | 윤성진 - 교보문고
파이썬으로 구현하는 로보어드바이저 | 로보어드바이저 시스템의 핵심 엔진을 개발했던 금융 AI 연구원들이 직접 쓴 책으로, 로보어드바이저를 구성하는 주요 포트폴리오 전략을 파이썬 코드와
product.kyobobook.co.kr
그래서 지난 주부터 책을 사서 읽고 있는데, 내용이 상당히 흥미롭다.
오렌지사과 님의 블로그를 오래 전부터 구독하면서 MDD와 CAGR 정도의 개념을 포트폴리오 배분에 참고하고 있었는데, 이 책은 포트폴리오 배분에 필요한 금융 수식과 함께 이를 소프트웨어적으로 구현하기 위한 코드를 제공한다.
예를 들어 3장부터 효율적 포트폴리오를 구성하기 위한 편입 비중을 직접 구할 수 있다는 코드를 소개한다.
(코드의 의미를 소개한다기보다는, 마법이나 직감이 아닌 코드로 포트폴리오를 계산할 수 있다는 것을 보여주고 싶었다.)
from typing import List, Optional, Dict
from pykrx import stock
import pandas as pd
import time
from pypfopt import EfficientFrontier
# 1. 한국거래소 데이터 스크래핑
class PykrxDataLoader:
def __init__(self, fromdate: str, todate: str, market: str = "-->"):
self.fromdate = fromdate
self.todate = todate
self.market = market
def load_stock_data(self, ticker_list: List, freq: str, delay: float = 1):
ticker_data_list = []
for ticker in ticker_list:
ticker_data = stock.get_market_ohlcv(
fromdate=self.fromdate,
todate=self.todate,
ticker=ticker,
freq="d",
adjusted=True,
)
ticker_data = ticker_data.rename(
columns={
"시가": "open",
"고가": "high",
"저가": "low",
"종가": "close",
"거래량": "volume",
"거래 대금": "trading_value",
"등락률": "change_pct",
}
)
ticker_data = ticker_data.assign(ticker=ticker)
ticker_data.index.name = "date"
ticker_data_list.append(ticker_data)
time.sleep(delay)
data = pd.concat(ticker_data_list)
# 거래가 중단되어 시가가 0원이었을 경우에는 종가 데이터로 덮어씌운다.
# loc의 첫 파라미터는 행에 대한 정보, 두 번째는 열에 대한 정보
data.loc[data.open == 0, ["open", "high", "low"]] = data.loc[
data.open == 0, "close"
]
if freq != "d":
rule = {
"open": "first",
"high": "max",
"low": "min",
"close": "last",
"volume": "sum",
}
data = (
data.groupby("ticker").resample(freq).apply(rule).reset_index(level=0)
)
data.__setattr__("frequency", freq)
return data
# 2. 주어진 기간동안의 기대수익을 리턴하는 함수
def calculate_return(ohlcv_data: pd.DataFrame):
close_data = (
ohlcv_data[["close", "ticker"]].reset_index().set_index(["ticker", "date"])
)
close_data = close_data.unstack(level=0)
close_data = close_data["close"]
print("close_data: ", close_data)
# 한 객체 내에서 행과 행의 차이를 현재값과의 백분율로 출력하는 메서드
# pct_change(1) = 비교할 간격 = 1
return_data = close_data.pct_change(1) * 100
return return_data.fillna(value=0)
# 3. 포트폴리오 편입 비중을 구하는 함수
#
# @params
# return_data: 수익률 데이터
# risk_aversion: 위험 회피 계수
def get_mean_variance_weights(
return_data: pd.DataFrame, risk_aversion: int
) -> Optional[Dict]:
# 평균 수익률 계산
expected_return = return_data.mean(skipna=False).to_list()
print("expected_return : ", expected_return)
# 공분산 (확률변수가 2가지일 때 얼마나 퍼져 있는가) 행렬 계산
cov = return_data.cov(min_periods=len(return_data))
print("cov : ", cov)
if cov.isnull().values.any() or cov.empty:
return None
# EfficientFrontier는 다양한 목적 함수를 최적화한다.
# 과거 평균 수익률을 기대수익률로 지정한다
ef = EfficientFrontier(
expected_returns=expected_return, cov_matrix=cov, solver="OSQP"
)
ef.max_quadratic_utility(risk_aversion=risk_aversion)
# 0에 가까운 편입 비중 처리 (clean_weights는 기본적으로 0.0001)
weights = dict(ef.clean_weights(rounding=None))
return weights
fromdate = "2024-01-01"
todate = "2024-12-31"
# 삼성전자, SK이노, 카카오, 현대차
ticker_list = ["005930", "096770", "035720", "005380"]
data_loader = PykrxDataLoader(fromdate=fromdate, todate=todate, market="KOSPI")
ohlcv_data = data_loader.load_stock_data(ticker_list=ticker_list, freq="ME", delay=1)
return_data = calculate_return(ohlcv_data)
print(get_mean_variance_weights(return_data=return_data, risk_aversion=3.07))지난 1년간의 주가 정보를 기반으로 기대수익을 구하고, EfficientFrontier 인스턴스가 마법처럼 포트폴리오를 배분해준 결과다.
# 기대수익이 가장 높은 포트폴리오를 구성하기 위해 계산된 비중
{
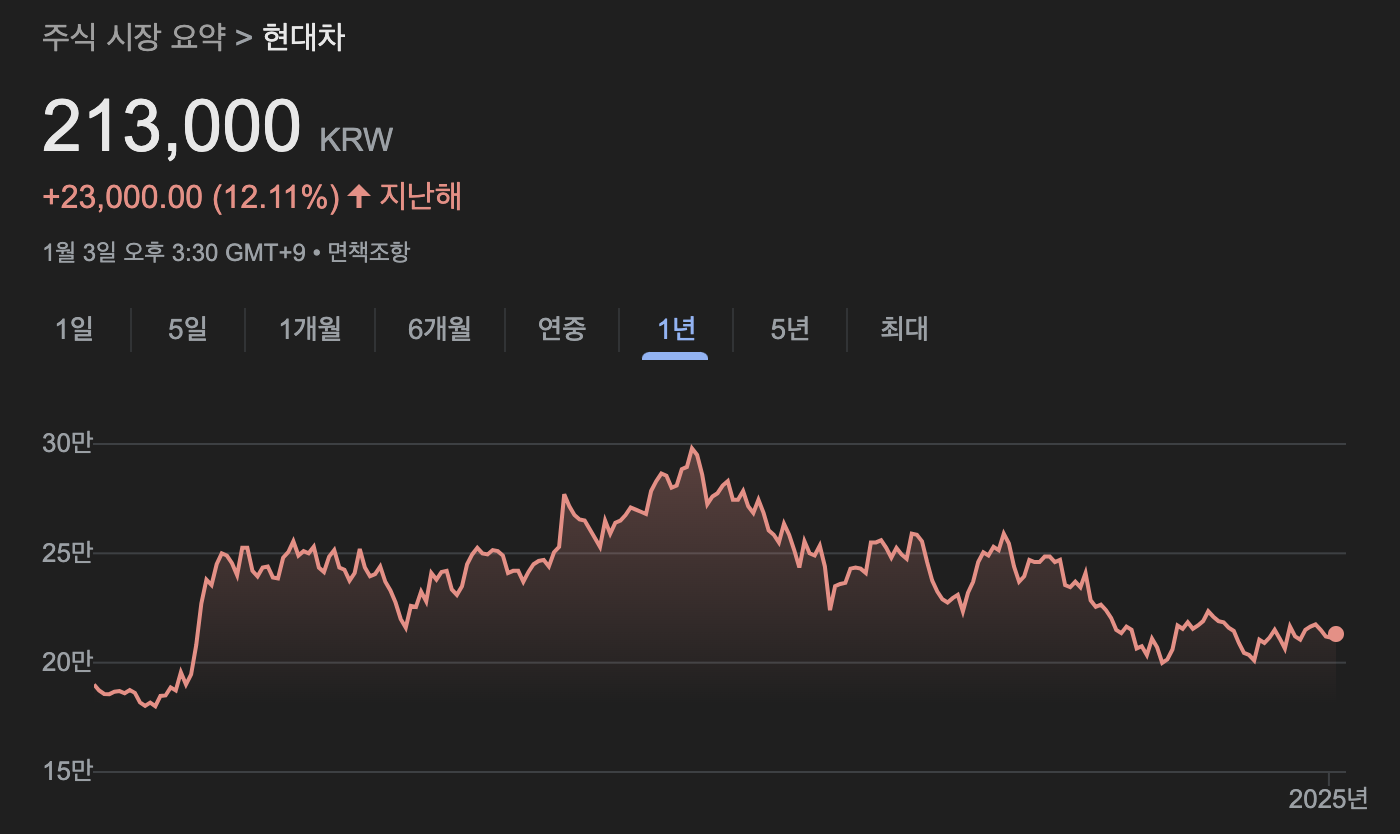
'005380': 0.0586880140708824, # 현대차
'005930': 0.1817195017162967, # 삼성전자
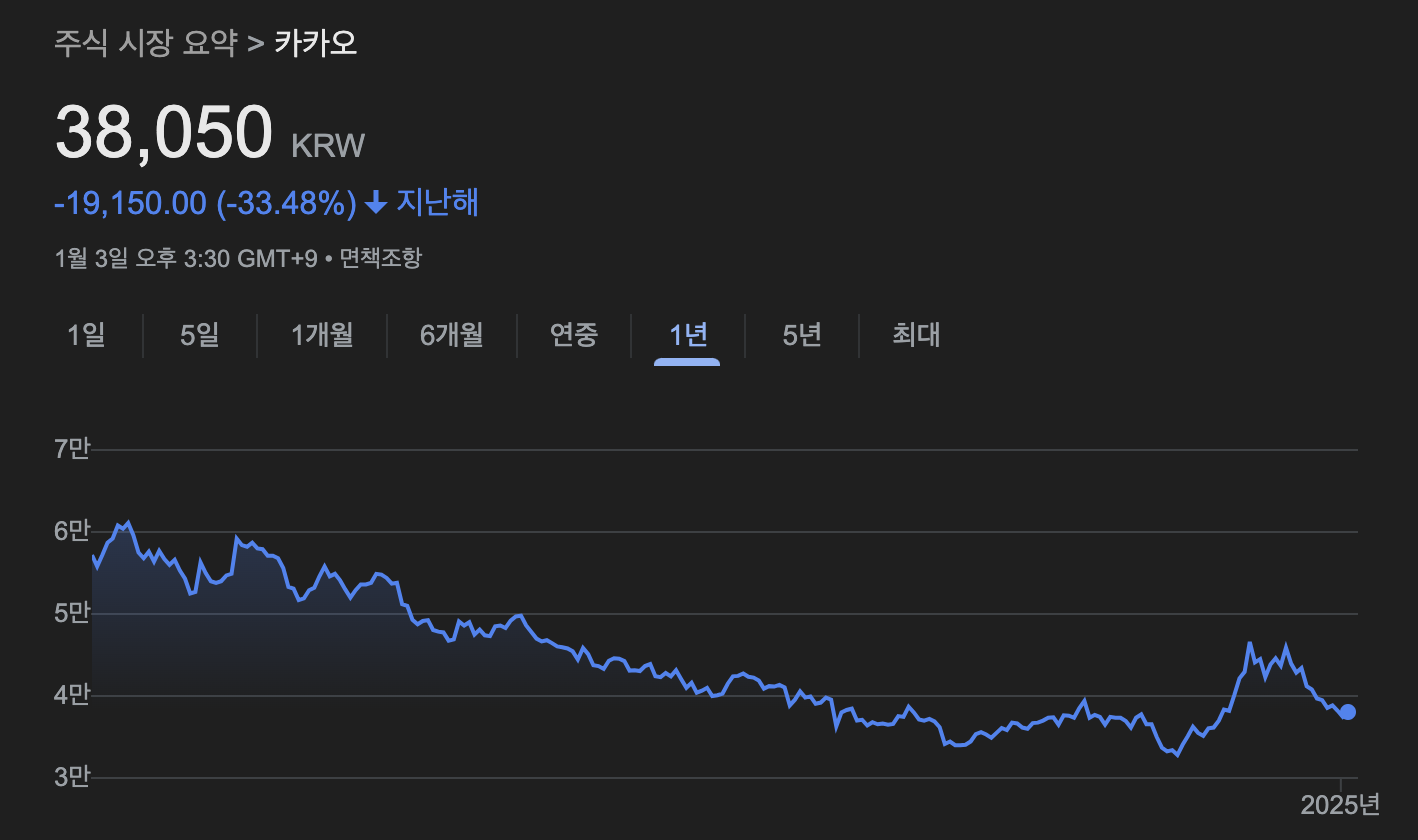
'035720': 0.5192497900232249, # 카카오
'096770': 0.2403426941895962 # SK이노
}으잉? 그런데 카카오의 비중이 가장 높게 나왔다.
만약 연초에 카카오에 들어갔다면 퍼포먼스가 좋지 않았을 텐데, 모델이 잘못된 것일까?
궁금해 TIGER 미국S&P500 과 나스닥100을 계산에 넣어 봤더니, 또 특이한 결과를 얻을 수 있었다.
먼저 기존 국장 포트폴리오에 S&P 500만을 추가했을 때는 납득할 만한 결과가 도출된다.
# 계산된 포트폴리오 비중
{
'005380': 0.040189957090838, # 현대차
'005930': 0.0, # 삼성전자
'035720': 0.0, # 카카오
'096770': 0.054764475901768, # SK이노
'360750': 0.9050455670073938 # S&P 500
}
# = 국내 개별주는 최소한으로 담고, 포트폴리오 대부분을 S&P로 채우면 기대수익이 가장 높다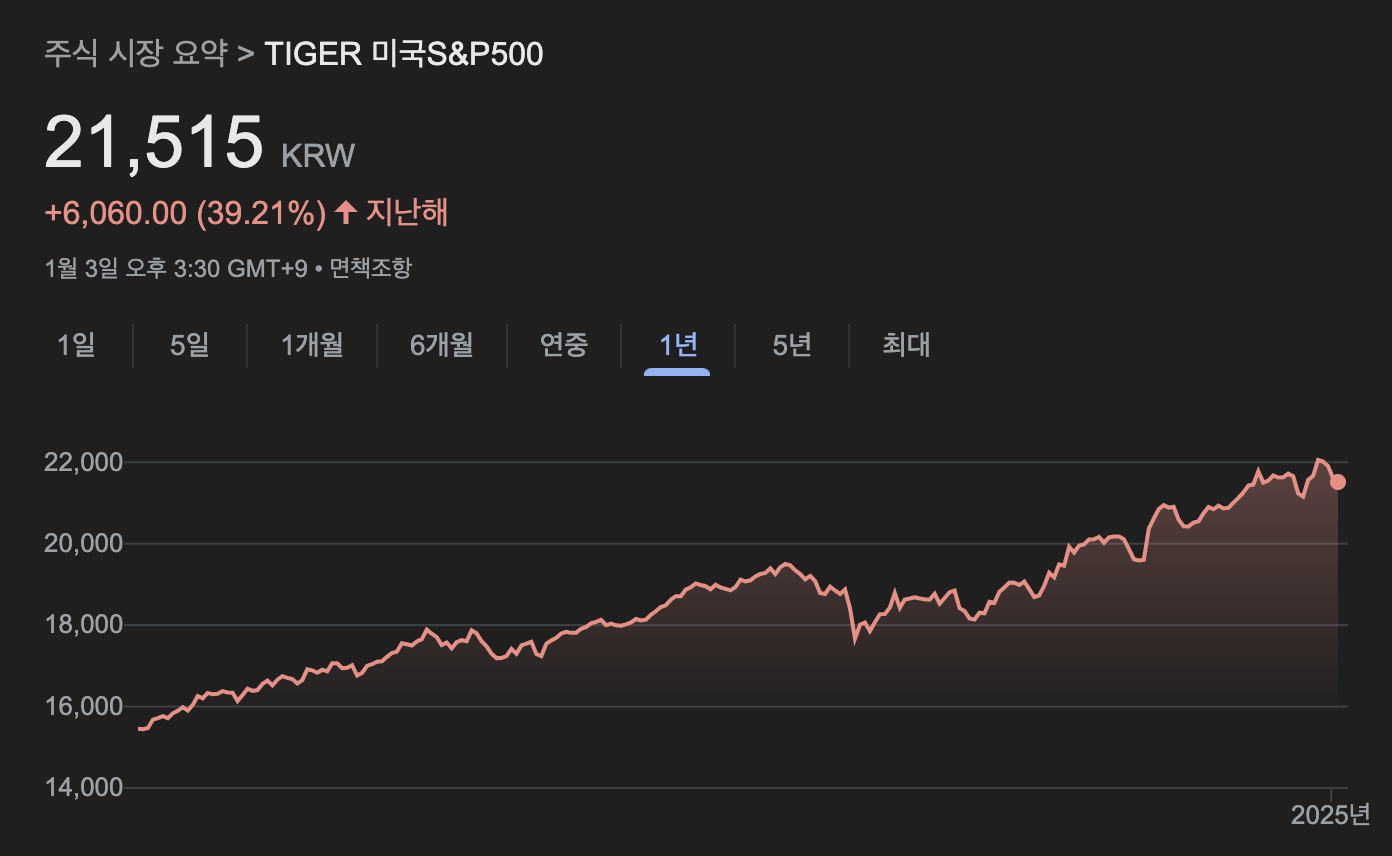
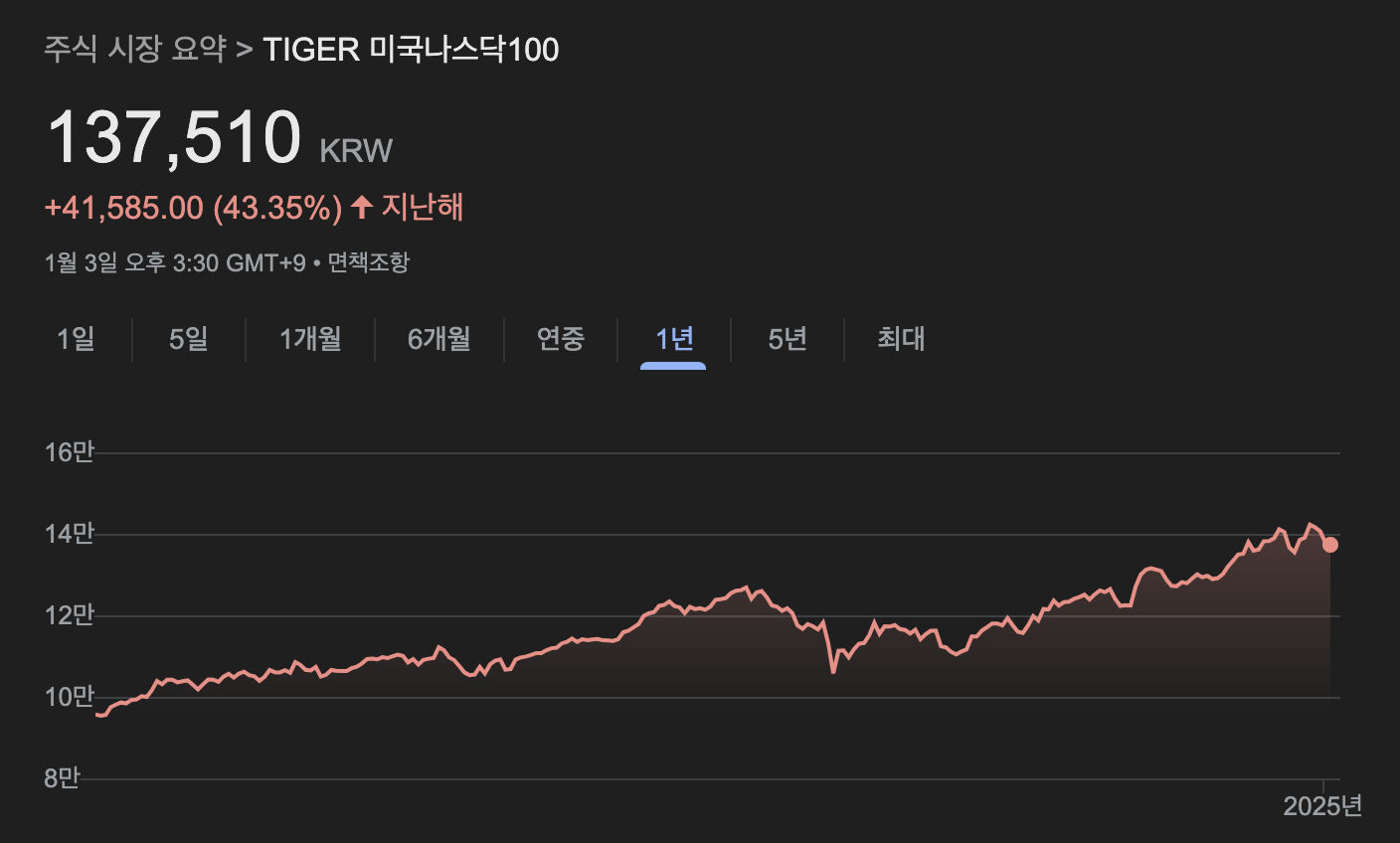
그런데 작년 나스닥 100은 S&P 500보다 더 나은 성과를 보였음에도 불구하고, 위 코드의 실행 결과는 나스닥 100을 포트폴리오에 추천하지 않고 있다.
# 계산된 포트폴리오 비중
{
'005380': 0.040189957090838, # 현대차
'005930': 0.0,
'035720': 0.0,
'096770': 0.054764475901768, # SK이노
'133690': 0.0, # 나스닥 100
'360750': 0.9050455670073942 # S&P 500
}이제 그 이유는 책을 계속 읽어가며 찾아볼 예정인데, 파이썬이 험난한 주식시장을 헤쳐나갈 정글도가 되어줄 것 같아 기대된다.
부디 내년엔 아래 짤을 쓸 일이 없길 바라며... 재밌는 것들을 배우면 종종 적어보려 한다.

'🧺 일상다반사' 카테고리의 다른 글
| 유데미 결제 에러 해결법 (4) | 2021.06.02 |
|---|---|
| 기여, 그리고 Thanks! (0) | 2021.02.12 |

