
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 컴퓨터공학
- 파이썬
- 클라우드
- 가상화
- TypeScript
- 블록체인
- docker
- 타입스크립트
- react
- 이더리움
- 자바스크립트
- 쿠버네티스
- es6
- 알고리즘
- k8s
- next.js
- CSS
- 프론트엔드
- 솔리디티
- VUE
- kubernetes
- 백준
- 웹
- BFS
- 이슈
- 백엔드
- JavaScript
- HTML
- AWS
- 리액트
- Today
- Total
즐겁게, 코드
캐시 메모리, 너는 누구니? 본문
오늘은 메모리계의 날쎈돌이, 캐시 메모리의 역할과 원리를 간단히 요약해보도록 하겠습니다.
✅ 읽기 전에 알려드려요!
이 글에서는 L1 ~ L3 캐시 구조 등 하드웨어적인 동작 원리에 대해서는 다루지 않으며, 캐시의 지역성만을 다룰 예정입니다. 🙂
캐시 메모리란?
먼저 캐시 메모리 란 처리속도가 다른 두 장치간의 속도차에 따른 병목 현상을 줄이기 위한 범용 메모리입니다.
만일 캐시가 존재하지 않는다면 RAM에서 데이터를 인출해오는 속도가 CPU가 태스크를 처리하는 속도보다 느리기 때문에 불필요하게 시간을 낭비해야 하지만, 실제로는 중간에 위치한 캐시 메모리가 둘 사이에서 데이터를 고속으로 전달해 줌으로써 속도 차이로 인한 병목을 어느정도 해결해 줄 수 있습니다.

그러나 캐시 메모리는 처리속도가 굉장히 빠른 대신, 용량이 작고 비싸다 는 치명적인 약점이 존재합니다.
✅ Tip. 메인 메모리와 캐시 메모리의 크기 및 구조 비교
현 세대 컴퓨터에 탑재되는 RAM이 보통 8 ~ 32GB 수준인데, 그에 비해 캐시 메모리는 32KB ~ 8MB 정도로 작습니다. 정말 작죠?
또, 아래의 셀 회로를 보면 캐시 메모리 쪽이 메모리를 구성하는 트랜지스터의 수가 훨씬 많음을 알 수 있습니다.
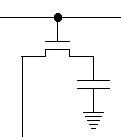
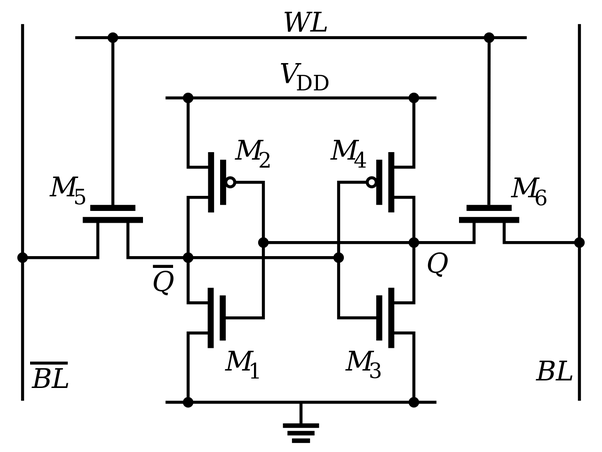
캐시 메모리는 자주 사용하는 프로그램이나 데이터를 미리 예측해 저장해두었다가 CPU에서 해당 데이터를 필요로 할 때 재빨리 넘겨주는 역할을 하는데요, 이를 위해 어떤 데이터가 자주 사용될지를 예측할 수 있어야만 합니다.
✅ 이 때, 원하는 데이터를 캐시가 예측해둔 데이터 중에서 불러오는데 성공한 비율을 캐시 적중률(Hit Rate) 라고 부릅니다.
적중률을 높여 캐시 성능을 끌어올리기 위해 다양한 하드웨어 부품과 알고리즘이 동원되기도 하지만, 이번 글에서는 캐시 메모리가 갖는 "지역성" 이라는 고유의 특성을 소개해도보록 하겠습니다. 🙂
캐시의 지역성 (Cache Locality)
캐시의 지역성은 시 · 공간적으로 가까운 데이터의 접근이 보다 원활하게 일어나는 성질로, 캐시는 이 성질로 적중률을 최대화해 효율적으로 동작할 수 있게끔 합니다.
캐시의 지역성은 크게 공간 지역성 과 시간 지역성 으로 나뉘는데요, 각 용어를 풀이하자면 다음과 같습니다.
- 공간 지역성 : 최근에 사용했던 데이터와 메모리 주소상 인접한 데이터가 캐시로부터 참조될 가능성이 높다는 특성
arr = [1, 2, 3, 4, 5]
print(arr[0]) # 어, 0번째 요소가 참조됐네? 혹시 1번째 요소도 사용할지 모르니 캐시에 넣어두자.
print(arr[1]) # 1번째 요소잖아! 어서 CPU로 넘겨 줘야겠다!- 시간 지역성 : 최근에 사용했던 데이터가 캐시에서 재참조될 가능성이 높다는 특성
name = "chanmin"
for i in range(100):
print(name) # name이 계속 참조되잖아! 어서 캐시에 넣어두고 재활용하자!캐싱 라인 (Caching Line)
캐시가 메모리에서 CPU로 아무리 데이터를 빨리 전달할 수 있다고 해도, 막상 캐시 내부에서 데이터를 찾는 데 시간이 오래 걸린다면 캐시를 사용하는 이유가 퇴색될 것입니다.
따라서 캐시는 데이터를 쉽게 검색하기 위해 빈번히 사용되는 데이터들의 주소들을 기록해 둔 태그를 만드는데요, 여러 태그를 하나로 묶은 자료구조를 캐싱 라인 이라고 합니다.
캐싱 라인의 매핑 방법
직접 매핑(Direct Mapping)
- 직접 매핑은 메인 메모리를 일정한 블록으로 나누어 각각의 블록을 캐시의 정해진 영역에 매핑하는 방법입니다.
제일 구현하기 쉽다는 장점이 있지만, 캐시 적중률이 낮아질 수 있고 하나의 캐시 메모리에서 참조하는 데이터가 둘 이상이 될 수 있어 충돌이 일어날 수 있다는 단점이 존재합니다.
완전 연관 매핑 (Fully Associative Mapping)
- 완전 연관 매핑은캐시 메모리의 빈 공간에 마음대로 주소를 매핑하는 방식으로, 매핑은 아주 간단하지만 캐시 메모리에서 데이터를 꺼내올 때 모든 데이터를 순회하면서 병렬적으로 검색해야 합니다.
- 그런데, 캐시처럼 빠른 동작을 요구하는 영역에서는 탐색을 위해 CAM(Content-Addressable Memory) 라는 특수한 형태의 메모리가 추가로 필요해 가뜩이나 비싼 캐시 메모리가 더 비싸진다는 단점이 존재합니다.
집합 연관 매핑 (Set Associative Mapping)
- 현재 대부분의 캐시 메모리에서 사용되는 방식으로, 직접 매핑과 완전 연관 매핑의 장점만을 엮은 방식입니다.
집합 연관 매핑은 캐시 메모리의 빈 공간에 마음대로 주소를 저장하되, 미리 정해둔 특정 영역에만 저장하는 방식입니다. - 이를 기반으로 직접 매핑에 비해 검색은 느리지만 저장이 빠르고, 완전 연관 매핑에 비해 검색은 빠르지만 저장이 느려 전반적으로 검색이나 저장에 치우치지 않은 성능을 보장할 수 있게 됩니다.